Steps to reproduce:
Have user A, ldap authenticated, password 123.
User A is logged in on Kibana, just doing his thing.
User A goes to LDAP and change his password to 456.
User A tries to do something in Kibana.
Stuff breaks ![]()
What we see happening, also looking at behaviour discussed in:
The user gets a white screen.
But if we look at the logs of Elasticsearch, we see strange behaviour.
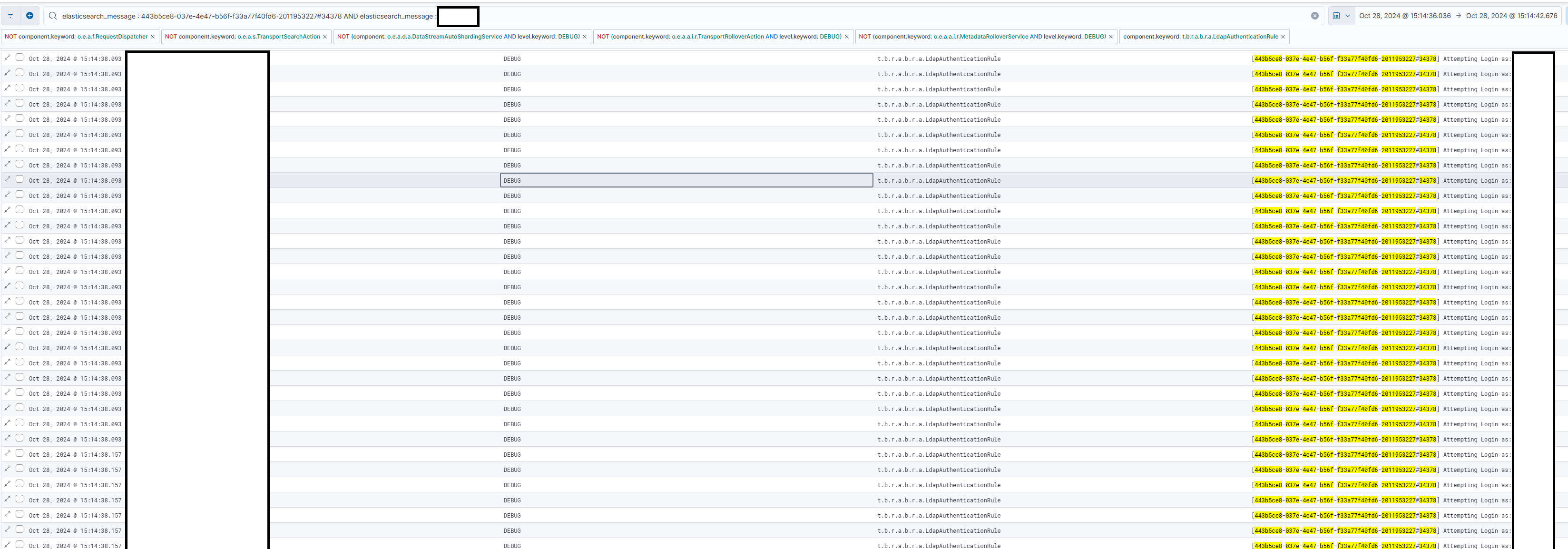
It tries to make a whole bunch of login attempts.
Each of those triggers a LDAP bind.
Look at the timing, all on the same milisecond.
All those connections trigger the circuit breaker for LDAP at some point.
But because the default connection pool is 30.
So the LDAP connector tries 30 binds with the old password, within a few miliseconds:
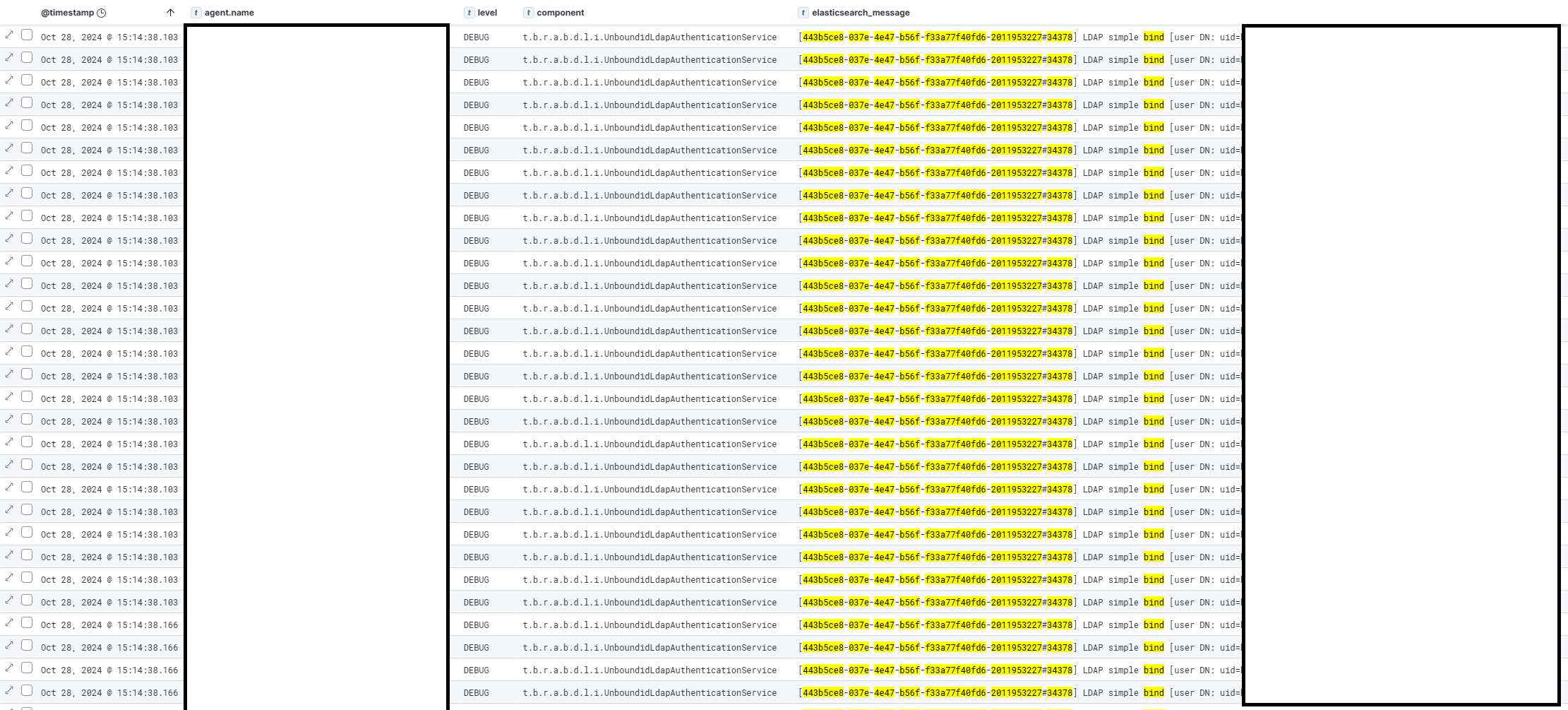
It seems due to the way LDAP session handling is setup, it uses the old credentials for this (User A hasn’t entered any new credentials yet).
This immediatly locks the account on LDAP side.
It goes on for a couple of thousand binds attempts, all going to circuit breaker or failing because account is locked on LDAP side now.
We applied a workaround by enabling LDAP cache and restricting the connection pool size to 1.
This makes for more predictable and manageable behaviour.
Now the user gets a white screen, should logoff and logon again.
But having a connection pool size of 1, is offcourse not ideal ![]()
Some version information:
ROR 1.59.0
ES/Kibana: 8.15.1
For completeness, but I don’t think it matters, we are on ROR Enterprise
Piece of config for LDAP:
Before:
ldaps:
- name: xxx
hosts:
- "ldaps://xxx:636"
- "ldaps://xxx:636"
ha: "ROUND_ROBIN"
ssl_trust_all_certs: true
ignore_ldap_connectivity_problems: false
bind_dn: "uid=xxx"
bind_password: "xxxx"
search_user_base_DN: "xxx"
user_id_attribute: "uid"
connection_timeout_in_sec: 20
request_timeout_in_sec: 15
Adding cache ttl and connection pool limit.
After:
ldaps:
- name: xxx
hosts:
- "ldaps://xxx:636"
- "ldaps://xxx:636"
ha: "ROUND_ROBIN"
ssl_trust_all_certs: true
ignore_ldap_connectivity_problems: false
bind_dn: "uid=xxx"
bind_password: "xxxx"
search_user_base_DN: "xxx"
user_id_attribute: "uid"
connection_timeout_in_sec: 20
request_timeout_in_sec: 15
cache_ttl_in_sec: 60
connection_pool_size: 1
Ideally you can set something up in a test environment on your side and check with the default connection pool and no cache.
If you can recreate the issue it would be great.
The above logs were made with Elasticsearch log level on debug.
I needed to screenshot those to take sections out simply due to the enourmous volumes of login (1 request triggers really thousands of logs regarding logins and ldaps)
I hope the above stories makes some sense and gives some guidance on what is happening.
Let me know if you need any specific details.