When a cluster is used often, login works consistently. However, when a cluster is not used frequently, the login tends to fail with “could not login”. Looking in the es logs shows the issue:
[2020-03-26T12:42:14,080][ERROR][t.b.r.a.b.Block ] [es2-3...] ldap-admin:
ldap_auth rule matching got an error LDAP returned code: timeout [85],
cause: result code='85 (timeout)' diagnostic message='The asynchronous operation
encountered a client-side timeout after waiting 30001 milliseconds for a response to arrive.' ...
LDAP login to these servers works on other services consistently.
What I’ve found to be an effective fix is to take any non-LDAP account (such as admin or the kibana user) and log in. Then, go to the readonlyrest tab and change anything - typically I change connection_timeout_in_sec - and save it. This forces ROR to reconnect to the LDAP servers, after which point LDAP auth works again. Once I’m logged in, I can run my update-ror script to push the contents of readonlyrest.yml into the index. I’ve tried doing this first but unless I change a value it reports that the contents are already up to date and this doesn’t trigger the LDAP reconnect.
Suggestions on how to avoid having to go through this each time I want to access a less-frequently accessed cluster? Some sort of LDAP keep-alive?
Ok, just so happens that one of the clusters that gets used infrequently is also the one that I can roll out new versions on the easiest. People keep asking “where are the logs for X?” and I keep telling them but man oh man I must be using expiring words or something because they keep bloody asking.
Instead of displaying the usual “Could not login” firefox now gives an error that the site couldn’t serve the page. Didn’t grab the exact error message, sorry for that, but I will if I can get it to do it again.
Stranger yet, I grabbed the kibana creds and logged in with that, only to see:
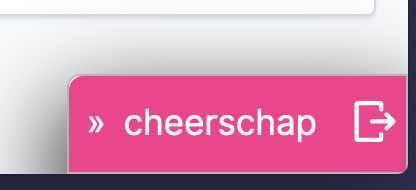
My LDAP cheerschap login failed - and this login was with the kibana user locally defined in the ror config. Logging out and logging back in with the same credentials got the login username set properly to kibana.
Subsequently logging out and logging in as my LDAP user succeeded but that’s to be expected as I changed and saved the ror config.
I’ve just read the first post and now I think I understand what is going on. It seems that when LDAP error 85 occurs, the connection is broken and cannot be used any more. But it comes back to pool and then cannot handle any other request.
But still, I’d be nice to see logs. We will try to reproduce it in our integration tests.
Yep, these LDAP servers are used for login and other services on the network, many of which are used infrequently, and those work consistently.
In terms of logs, here’s the related logs from this morning:
[2020-03-30T15:06:00,163][ERROR][t.b.r.a.b.d.l.i.UnboundidLdapAuthenticationService] [bz1es2-3.bb.internal.maas360.com] LDAP getting user CN returned error: [code=85 (timeout), cause=result code='85 (timeout)' diagnostic message='The asynchronous operation encountered a client-side timeout after waiting 29999 milliseconds for a response to arrive.']
[2020-03-30T15:06:00,163][ERROR][t.b.r.a.b.d.l.i.UnboundidLdapAuthenticationService] [bz1es2-3.bb.internal.maas360.com] LDAP getting user operation failed.
[2020-03-30T15:06:00,163][ERROR][t.b.r.a.b.Block ] [bz1es2-3.bb.internal.maas360.com] ldap-admin: ldap_auth rule matching got an error LDAP returned code: timeout [85], cause: result code='85 (timeout)' diagnostic message='The asynchronous operation encountered a client-side timeout after waiting 29999 milliseconds for a response to arrive.'
tech.beshu.ror.accesscontrol.blocks.definitions.ldap.implementations.LdapUnexpectedResult: LDAP returned code: timeout [85], cause: result code='85 (timeout)' diagnostic message='The asynchronous operation encountered a client-side timeout after waiting 29999 milliseconds for a response to arrive.'
at tech.beshu.ror.accesscontrol.blocks.definitions.ldap.implementations.BaseUnboundidLdapService.$anonfun$ldapUserBy$2(UnboundidLdapService.scala:240) ~[?:?]
at monix.eval.internal.TaskRunLoop$.startFull(TaskRunLoop.scala:170) ~[?:?]
at monix.eval.Task$.unsafeStartNow(Task.scala:4582) ~[?:?]
at monix.eval.internal.TaskBracket$BaseStart$$anon$1.onSuccess(TaskBracket.scala:187) ~[?:?]
at monix.eval.internal.TaskRunLoop$.startFull(TaskRunLoop.scala:165) ~[?:?]
at monix.eval.Task$.unsafeStartNow(Task.scala:4582) ~[?:?]
at monix.eval.internal.TaskBracket$BaseStart.apply(TaskBracket.scala:174) ~[?:?]
at monix.eval.internal.TaskBracket$BaseStart.apply(TaskBracket.scala:164) ~[?:?]
at monix.eval.internal.TaskRestartCallback.run(TaskRestartCallback.scala:65) ~[?:?]
at monix.execution.internal.Trampoline.monix$execution$internal$Trampoline$$immediateLoop(Trampoline.scala:66) ~[?:?]
at monix.execution.internal.Trampoline.startLoop(Trampoline.scala:32) ~[?:?]
at monix.execution.schedulers.TrampolineExecutionContext$JVMOptimalTrampoline.startLoop(TrampolineExecutionContext.scala:143) ~[?:?]
at monix.execution.internal.Trampoline.execute(Trampoline.scala:40) ~[?:?]
at monix.execution.schedulers.TrampolineExecutionContext.execute(TrampolineExecutionContext.scala:64) ~[?:?]
at monix.execution.schedulers.BatchingScheduler.execute(BatchingScheduler.scala:50) ~[?:?]
at monix.execution.schedulers.BatchingScheduler.execute$(BatchingScheduler.scala:47) ~[?:?]
at monix.execution.schedulers.AsyncScheduler.execute(AsyncScheduler.scala:31) ~[?:?]
at monix.eval.internal.TaskRestartCallback.start(TaskRestartCallback.scala:56) ~[?:?]
at monix.eval.internal.TaskRunLoop$.executeAsyncTask(TaskRunLoop.scala:592) ~[?:?]
at monix.eval.internal.TaskRunLoop$.startFull(TaskRunLoop.scala:120) ~[?:?]
at monix.eval.internal.TaskRunLoop$.$anonfun$restartAsync$1(TaskRunLoop.scala:222) ~[?:?]
at java.util.concurrent.ForkJoinTask$RunnableExecuteAction.exec(ForkJoinTask.java:1402) [?:1.8.0_242]
at java.util.concurrent.ForkJoinTask.doExec(ForkJoinTask.java:289) [?:1.8.0_242]
at java.util.concurrent.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1056) [?:1.8.0_242]
at java.util.concurrent.ForkJoinPool.runWorker(ForkJoinPool.java:1692) [?:1.8.0_242]
at java.util.concurrent.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:157) [?:1.8.0_242]
[2020-03-30T15:06:30,679][ERROR][t.b.r.a.b.d.l.i.UnboundidLdapAuthorizationService] [bz1es2-3.bb.internal.maas360.com] LDAP getting user CN returned error: [code=85 (timeout), cause=result code='85 (timeout)' diagnostic message='The asynchronous operation encountered a client-side timeout after waiting 29999 milliseconds for a response to arrive.']
[2020-03-30T15:06:30,680][ERROR][t.b.r.a.b.d.l.i.UnboundidLdapAuthorizationService] [bz1es2-3.bb.internal.maas360.com] LDAP getting user operation failed.
[2020-03-30T15:06:30,680][ERROR][t.b.r.a.b.Block ] [bz1es2-3.bb.internal.maas360.com] ldap-all: ldap_auth rule matching got an error LDAP returned code: timeout [85], cause: result code='85 (timeout)' diagnostic message='The asynchronous operation encountered a client-side timeout after waiting 29999 milliseconds for a response to arrive.'
tech.beshu.ror.accesscontrol.blocks.definitions.ldap.implementations.LdapUnexpectedResult: LDAP returned code: timeout [85], cause: result code='85 (timeout)' diagnostic message='The asynchronous operation encountered a client-side timeout after waiting 29999 milliseconds for a response to arrive.'
at tech.beshu.ror.accesscontrol.blocks.definitions.ldap.implementations.BaseUnboundidLdapService.$anonfun$ldapUserBy$2(UnboundidLdapService.scala:240) ~[core-1.19.3.jar:?]
at monix.eval.internal.TaskRunLoop$.startFull(TaskRunLoop.scala:170) ~[monix-eval_2.12-3.0.0.jar:3.0.0]
at monix.eval.Task$.unsafeStartNow(Task.scala:4582) ~[monix-eval_2.12-3.0.0.jar:3.0.0]
at monix.eval.internal.TaskBracket$BaseStart$$anon$1.onSuccess(TaskBracket.scala:187) ~[monix-eval_2.12-3.0.0.jar:3.0.0]
at monix.eval.internal.TaskRunLoop$.startFull(TaskRunLoop.scala:165) ~[monix-eval_2.12-3.0.0.jar:3.0.0]
at monix.eval.Task$.unsafeStartNow(Task.scala:4582) ~[monix-eval_2.12-3.0.0.jar:3.0.0]
at monix.eval.internal.TaskBracket$BaseStart.apply(TaskBracket.scala:174) ~[monix-eval_2.12-3.0.0.jar:3.0.0]
at monix.eval.internal.TaskBracket$BaseStart.apply(TaskBracket.scala:164) ~[monix-eval_2.12-3.0.0.jar:3.0.0]
at monix.eval.internal.TaskRestartCallback.run(TaskRestartCallback.scala:65) ~[monix-eval_2.12-3.0.0.jar:3.0.0]
at monix.execution.internal.Trampoline.monix$execution$internal$Trampoline$$immediateLoop(Trampoline.scala:66) [monix-execution_2.12-3.0.0.jar:3.0.0]
at monix.execution.internal.Trampoline.startLoop(Trampoline.scala:32) [monix-execution_2.12-3.0.0.jar:3.0.0]
at monix.execution.schedulers.TrampolineExecutionContext$JVMOptimalTrampoline.startLoop(TrampolineExecutionContext.scala:143) [monix-execution_2.12-3.0.0.jar:3.0.0]
at monix.execution.internal.Trampoline.execute(Trampoline.scala:40) [monix-execution_2.12-3.0.0.jar:3.0.0]
at monix.execution.schedulers.TrampolineExecutionContext.execute(TrampolineExecutionContext.scala:64) [monix-execution_2.12-3.0.0.jar:3.0.0]
at monix.execution.schedulers.BatchingScheduler.execute(BatchingScheduler.scala:50) [monix-execution_2.12-3.0.0.jar:3.0.0]
at monix.execution.schedulers.BatchingScheduler.execute$(BatchingScheduler.scala:47) [monix-execution_2.12-3.0.0.jar:3.0.0]
at monix.execution.schedulers.AsyncScheduler.execute(AsyncScheduler.scala:31) [monix-execution_2.12-3.0.0.jar:3.0.0]
at monix.eval.internal.TaskRestartCallback.start(TaskRestartCallback.scala:56) [monix-eval_2.12-3.0.0.jar:3.0.0]
at monix.eval.internal.TaskRunLoop$.executeAsyncTask(TaskRunLoop.scala:592) [monix-eval_2.12-3.0.0.jar:3.0.0]
at monix.eval.internal.TaskRunLoop$.startFull(TaskRunLoop.scala:120) [monix-eval_2.12-3.0.0.jar:3.0.0]
at monix.eval.internal.TaskRestartCallback.syncOnSuccess(TaskRestartCallback.scala:101) [monix-eval_2.12-3.0.0.jar:3.0.0]
at monix.eval.internal.TaskRestartCallback.onSuccess(TaskRestartCallback.scala:74) [monix-eval_2.12-3.0.0.jar:3.0.0]
at monix.eval.internal.TaskShift$Register$$anon$1.run(TaskShift.scala:65) [monix-eval_2.12-3.0.0.jar:3.0.0]
at java.util.concurrent.ForkJoinTask$RunnableExecuteAction.exec(ForkJoinTask.java:1402) [?:1.8.0_242]
at java.util.concurrent.ForkJoinTask.doExec(ForkJoinTask.java:289) [?:1.8.0_242]
at java.util.concurrent.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1056) [?:1.8.0_242]
at java.util.concurrent.ForkJoinPool.runWorker(ForkJoinPool.java:1692) [?:1.8.0_242]
at java.util.concurrent.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:157) [?:1.8.0_242]
[2020-03-30T15:06:30,684][INFO ][t.b.r.a.l.AccessControlLoggingDecorator] [bz1es2-3.bb.internal.maas360.com] FORBIDDEN by default req={ ID:663354327-1515145325#19136717, TYP:RRAdminRequest, CGR:N/A, USR:cheerschap (attempted), BRS:false, KDX:null, ACT:cluster:admin/rradmin/refreshsettings, OA:10.2.111.52/32, XFF:null, DA:10.2.111.23/32, IDX:<N/A>, MET:GET, PTH:/_readonlyrest/metadata/current_user, CNT:<N/A>, HDR:Authorization=<OMITTED>, Connection=keep-alive, Content-Length=0, Host=bz1es2-3.bb.internal.maas360.com:9200, HIS:[local-admin-> RULES:[auth_key_unix->false]], [local-logstash-> RULES:[auth_key_unix->false]], [local-kibana-> RULES:[auth_key_unix->false]], [local-puppet-> RULES:[auth_key_unix->false]], [local-jenkins-> RULES:[auth_key_unix->false]], [elastalert-> RULES:[auth_key_unix->false]], [fluentbit-> RULES:[auth_key_unix->false]], [ldap-admin-> RULES:[ldap_auth->false]], [ldap-all-> RULES:[ldap_auth->false]], [localhost-> RULES:[hosts->false]] }
I’ve got exactly the same problem. I can see that logs are provided abowe so I am not pasting any duplicates but I can confirm that this problem exists with plugin version 1.19.3 an ES 6.8.7. Please also notify me if You fix it. It’s a little bit critical for my company right now
Have you seen my workaround? If you have a local user with appropriate permissions, you can log in as that user and make some minor change to the ROR config, and when you save it’ll cause a reconnect.
It could also be done from the command line but that’s a little more involved, I’ve got a script I could share if that would be helpful.
Any update on where this stands? I had to create a new cluster due to load issues on the other, and folks are not logging into this one regularly so I’m having to run my workarounds each time I want to log in, and I’m getting pinged regularly from someone who is trying to log in. Seems like it really needs plenty of steady activity to keep the LDAP connection from dropping, and it’s getting frustrating to have to keep working around this. I wish I had Xsi’s option of moving to basic auth.